Spoiler Comment classification using MindsDB, Zero-shot-text-classification and Gradio.

Dabble with Machine Learning during the day, drool on anime and Kdrama by night, I love breaking things to its core concepts and teach others, experiment with state-of-the art ML algorithms and decipher research papers in simple terms.
This is my entry for the MindsDB x hashnode hackathon
If you are any average anime fan like me who likes to stream shows on online free streaming sites and also like reading comments chances are that you've had your favorite anime shows spoiled for you before you even get a chance to watch them? Spoilers on online anime streaming sites have become a major problem, ruining the excitement and anticipation of watching a new episode. You may think you're safe scrolling through your social media feed, only to be hit with a major plot twist or character death. It's time to take a stand against spoilers and demand a spoiler-free viewing experience. Let's see how to preserve the magic of anime and enjoy it as it was meant to be seen – without any unwanted spoilers using the power of machine learning and MindsDB.
In this tutorial, we will use MindsDB and Zero-shot-text classification to identify spoiler comments and build an interactive demo using gradio.
Zero-shot text classification
We will be doing so with an ML paradigm called zero shot classification, particularly for texts. Zero-shot text classification is a natural language processing technique that allows an AI model to classify text into multiple categories without being trained on any examples from those categories. This means that the model can classify text even for categories that it has never seen before, making it a powerful tool for handling unseen data. This approach relies on the use of pre-trained language models that have learned to understand the relationships between different words and phrases in a language. Zero-shot text classification is useful because it allows for more flexible and efficient text classification, enabling businesses to quickly adapt to changing trends and needs. With this technique, AI models can classify text in multiple languages and across different domains, making it a valuable asset for many applications, such as sentiment analysis, document classification, and more.
I have leveraged this ML technique since I don't have any dataset where there is a set of comments and also their labels as in spoiler or not. It's fairly easy to perform zero-shot classification and I will reference a hugging face doc that shows us to do so https://huggingface.co/tasks/zero-shot-classification . The point of interest is this part
from transformers import pipeline
pipe = pipeline(model="facebook/bart-large-mnli") pipe("I have a problem with my iphone that needs to be resolved asap!", candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"], )
and this is the output
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
They are using the BART-large-MNLI pre-trained model from the Transformers library. The pipeline() function is used to create an instance of the model and define its task as text classification. The pipe() function is then used to classify the input text, "I have a problem with my iphone that needs to be resolved asap!", into multiple categories specified in candidate_labels. The output of the function is a dictionary containing the original input text, the predicted labels sorted by their scores, and the corresponding scores. In this example, the highest scoring label for the input text is "urgent" with a score of 0.504, followed by "phone", "computer", "not urgent", and "tablet".
Intergrating MindsDB
We will mostly use this structure but integrate MindsDB into our workflow to make things interesting. MindsDB is a powerful machine learning tool that enables users to perform predictive analytics directly on tables within their database using standard SQL. This allows for a wide range of interesting use cases, such as predicting customer churn rates, forecasting sales trends, and identifying anomalies in large datasets. Additionally, MindsDB's ability to integrate with existing business intelligence tools and applications means that users can easily visualize their predictions and insights, making it a valuable asset for data-driven decision-making. Some other interesting use cases of MindsDB include predicting equipment failures in manufacturing, identifying fraudulent transactions in financial services, and optimizing supply chain logistics. With MindsDB, businesses and organizations can leverage their data to gain valuable insights and improve their operations.
We can use this powerful feature to our advantage by performing Zero-shot classification directly on the database as well as doing model predictions on the app client side.
Let's see a very simple workflow to do so.
Create an account on MindsDB and either use the cloud instance or host your own instances https://cloud.mindsdb.com/home
head over to your instance

and add your dataset. In this case, our would be a simple dataset that contains comments from anime videos that I scraped from Youtube(I chose youtube comments it's easy to get the from their api and you can also use external scraping bots like https://botster.io/ and mostly because those online streaming sites mostly don't provide any api to use their sites programmatically).
I uploaded my scraped files that were in csv format using the handy
upload_filefunctionality
Once you upload, your files reside here
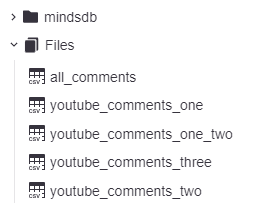
once you add files, MindsDB treats those files as any other sql tables that you can run sql queries against. Running queries and analysing your data is really intuitive and fast, here's a sample query to view the contents of our files .
SELECT * FROM files.all_comments;
which shows me the contents of my files, like so

I then created a zero shot classification model using this query from their docs
CREATE MODEL mindsdb.zero_shot_tcd PREDICT topic USING engine = 'huggingface', task = 'zero-shot-classification', model_name = 'facebook/bart-large-mnli', input_column = 'Text', candidate_labels = ["spoiler", "friendly", "neutral"];
This piece of code will create a model called zero_shot_tcd and pull all model data of zero shot classification task including model artifacts in your workspace or server. It will use the input_column parameter which is the Text column in our original files that were converted in tables to make the predictions and save your predictions in a new column called topic. Once you run this query it will take a while to generate everything. You can check the status of this job by running this query
SELECT *
FROM mindsdb.models
WHERE name = 'zero_shot_tcd';
once it displays status complete you are ready to use the model

Running predictions
We can run predictions in several ways. The simplest is to run a SQL query like this
SELECT * FROM zero_shot_tcd
WHERE Text='I will never forgive gege for killing off nanami this early';
This is a sample comment that ruined my experience of one of my favourite manga and anime JJK when I was watching it on an online streaming site. let's see what our model thinks this comment is

Great. It identified the topic with very high probability and is also showing us the probabilities of each label class.
Running inference in your app
We will now see a simple demo of deploying an app using Gradio and mindsdb_sdk . Install the dependencies using these commands
pip install gradio
pip install mindsdb_sdk
pip install pandas
Import the libraries and connect to your mindsdb instance like so, make sure to put the same email and password you used to create the account.
import mindsdb_sdk
import pandas as pd
import gradio as gr
server = mindsdb_sdk.connect('https://cloud.mindsdb.com', login="<your-email>", password="<your-password>")
After you've connected to the instance, retrieve the running database and find your desired model like this
project = server.get_project("mindsdb")
model = project.list_models()[0]
Since I have only one model, I retrieved the first item in the model list. As a useful side note, the model prediction will work in tandem with pandas as the model expects a tabular structure like that in databases. This is a sample code that you can run to verify this observation:
vars = {"Text":"I can't believe he is dead"}
data = pd.DataFrame(vars, index=[0])
res = model.predict(data)
print(res["topic"][0])
The gradio app:
A simple gradio app will wrap all this functionality in a python file.
def classify_text(text):
# Classify text using the loaded model
var = {"Text": text}
data = pd.DataFrame(var, index=[0])
result = model.predict(data)
label = result['topic'][0]
#score = result['score']
return f"{label}"
# Create Gradio interface
iface = gr.Interface(
fn=classify_text,
inputs=gr.inputs.Textbox(label="Enter text to classify"),
outputs="text",
title="Identify spoiler comments with zero-shot text classification",
description="Input a sentence here"
)
# Launch the interface
iface.launch()
And we will get a nice little UI that shows us that the comment is a spoiler

You can deploy this app in any cloud server and get predictions from anywhere on the internet. A practical usage in this context would be to batch predict a database of comments and blur the spoiler comments in any online video streaming community without any manual moderation.



